Bonus: AI Rocky is now 99% smarter than hue-mon {human} about identify dog and cat breeds. All it takes is four additional lines of code. (section #A.11 Bonus, Feb. 2021)
Welcome to the “Fast.ai Book Study Group” (G1FA) project. It is a new journey in the “Demystify AI” series.

The only thing these journeys have in common is the problems are taken from the real-world Artificial Neural Network (ANN) project. I have worked on them, coded them, cried over them, and sometimes had a flash-of-insight or an original thought about them.
The journeys are a fun and fascinating insight into an AI Scientist and Big-Data Scientist’s daily work. They are for colleagues and AI students, but I hope that you, a gentle reader, would enjoy them too.
The G1FA is the sixth in the series. It is not like previous journeys because I based it entirely on the excellent “Deep Learning for Coders with Fastai and PyTorch: AI Applications Without a Ph.D.” book by Jeremy Howard and Sylvain Gugger. The G1FA journey covers only the first chapter.
The book is an excellent primer to the Fast.ai courses. I have studied and practiced Fast.ai in my work for years, and finally, last Christmas, I got the paper book as a gift. Furthermore, Jeremy and Sylvain wrote the book on Jupyter notebooks, and the notebooks are freely available online, GitHub.
Mind Explosion!
It is a Jupyter notebook, so naturally, I cloned it from Github, organized a study group from the “San Ramon Professional Development BizTech and AI Meetup,” and started hacking it.
Before diving more in-depth, you wonder how it relates to the “Demystify AI” series when the book does so well explaining ANN. A significant part of the series is giving the readers a peek into AI scientists’ everyday issues. Without a doubt, the biggest fear is being outdated.
Like in every profession, we must keep up with technological advances. It is not exaggerating to say the following in the AI and ANN field. Practices and concepts that you learned three to five years ago are outdated or substantially updated. For example, the “fit learning rate” is the predominant hyper-parameters in ANN. Three years ago, experienced AI scientists were making “educated” guesses on the fit-rate, key the “eye roles” sequence.
With Fast.ai, Jeremy based his “learn_rate_finder()” in Leslie N. Smith’s “Super-Convergence: Very Fast Training of Neural Networks Using Large Learning Rates” paper. Coupled with the Fast.ai exclusive “discriminate learning rate” concept, ANN surpasses expectations in real-world applications.
As an analogy, you are entering the race with a motorcycle while your colleagues use a three-year-old bicycle.
I am a visual thinker programmer, so I am not contenting with reading the book and pressing “Shift-Enter.” As with all the “Demystify AI” series, I encourage you to hack the notebook and make it your journey. Once you internalize the knowledge, it is yours forever.
The “play first” learning method is akin to the “Making Learning Whole: How Seven Principles of Teaching Can Transform Education” by David Perkins. Jupyter notebook is the best implementation of the “play first” philosophy for learning AI, coding, and math.
I mind-mapped everything that I read, i.e., drawing diagrams, but with code rather than a pencil. Furthermore, I took the fully functional code in the notebook and refactored it into an object, i.e., a Python class. As a result, I have fun creating this journey for you.
I classify the G1FA as a “sandbox” project with a study group. In other words, it is a fun, experimental project focusing on solving one problem. Each member of the group creates a unique journey and shares it.
So if you are ready, let’s take a collective calming breath … … and begin.
2 — The Journey
The power of the Jupyter notebook is interactive and individualized. The best method to learn is to make the journey your own.

The first step is to choose and name your canine companion. Since we need someone with a solid understanding of Fast.ai version 1.0, so the natural choice is “Rocky.” His AI knowledge is solid as a rock. :-)
Typically, a dog name is chosen, e.g., “Chevy,” “Fordy,” or “Cadila,” but be warned, don’t name it after your cat because a feline will not follow any commands.
If you are serious about learning, start hacking by changing the companion name to your preference. Jupyter notebook allows you to add notes, add new codes, and hack Rocky’s code.
As a good little programmer, Rocky (or insert your companion name here) starts by creating an object or class.
The notebook is the Fastbook’s “01_intro.ipynb”, and the Rocky addition sections begin with the “A.x @” label.
Rocky will skip copying the original text from the Fastai-Book and the code-cells. He only copy his additional sections including the output of his code-cells.
Please visit Rocky’s “fastaibook_01_intro_d0hz.ipynb” Jupyter notebook on GitHub to view the code.
When copying the code into Atom’s project, Rocky would add the methods during the class definition, but he will hack-it and add new class functions throughout the notebook journey. Section “A.3 and A.4” are part of the setup code. There is no output so that nothing will be copied here.
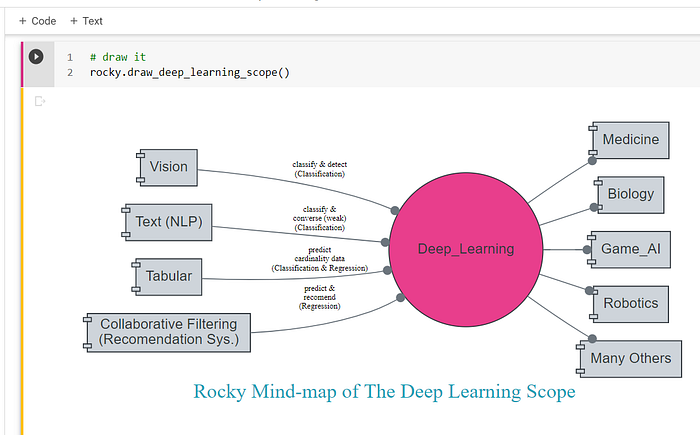
5 — Draw Deep Learning Scope
Rocky is a visual thinker, and he likes to draw. As Rocky fonds to say, “a picture worth a thousand words.” It is because Rocky is a canine, and dogs are not known for their reading talent. The fastbook has a cool “graph vector” method. Rocky wants to learn it. The document is at https://graphviz.org/about/.
The “fastbook.gv()” method is a bit limited, so Rocky will hack it and create his function based on the same library, “graphviz.” The new graph function parameters are as follows.
- graph = the gv-string representing the graph elements and links.
- edge_color = the color of the line linking between two elements.
- label = the label for the graph.
- direction = “LR” (default left-to-right horizontal), “TB” (top-to-bottom vertical).
- default_shape = “oval” (default), circle, box, diamond, triangle, component, and … more shape at https://graphviz.org/doc/info/shapes.html
- arrow_head = “normal” (default), dot, none, diamond, and … more arrow type at https://graphviz.org/doc/info/attrs.html#k:arrowType
- bgcolor = format: “#RGB” or “#RGBA”, “#dee2e6” gray (default).
- is_fill = True (default) or False. It is the element color. The default is lite gray.
- fill_color = format: “#RGB”, “#ced4da” (default).
- label_color = the font color of the label. The default is #17a2b8.
- graph_size = limit to output graph size. The default is no limit.
- node_font_color = the base font color for the element.
- engine = the layout engine. The possible values are “dot (default), circo, neato, fdp, osage, and twopi.” There is not much information about the layout engine. A good site where you can try out different layout engines is GraphVizOnline.
- (more hacking for gv-string) Additional parameters for the “node, graph, and edge” is at https://graphviz.org/doc/info/attrs.html
6 — A Brief History Visually
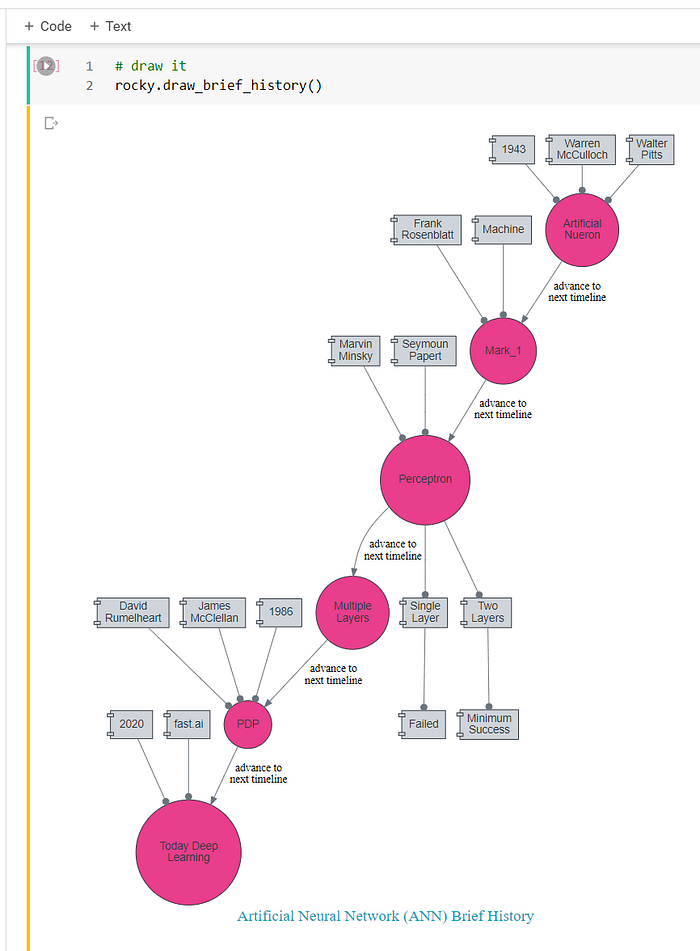
Study history is not Rocky’s favorite skill. He likes to fetch, run, hike, and especially roll. It is so funny, “…rock and roll.” :-)
So mind-mapping is how Rocky chooses to remember history. He imagines the pink-dots are watering holes along his hike. Canine can only see green and blue shade, so “pink” to Rocky is more like blue-ish.
7 — Visualize Fast.ai Team

Fast.ai is the fastest-growing ANN community. It is because Jeremy has unselfishly shared his knowledge and demystifies AI, and he made it an opensource and freely available. Rocky has learned Google TensorFlow and Keras before finding Fast.ai. With Google TensorFlow relying on memorization, it is like learning to play chess by mimicking existing moves, while Fast.ai explaining the rules that govern how each of the chess pieces could move.
Fast.ai code and documentation are built using Jupyter notebook, which is one thousand times better than videos, books, blogs, podcasts, and traditional classroom lecturing format.
“So … who are these hue-mons?” {humans}
8 — Visualize Deep Learning Process

Rocky agreed with the notebook’s learning philosophy. He knows that the philosophy is based on professor David Perkins’s “Making Learning Whole” book, but Rocky thinks it is more like Nike’s slogan “Just do it.” Does Nike make shoes for canine?
9 — Visualize Deep Learning Dev-Stack
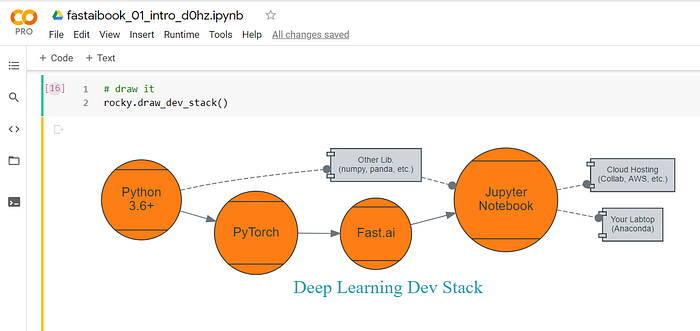
Rocky has been using Jupyter Notebooks for the past two years, and he loves it. Rocky starts out installing Anaconda and Python on his laptop. After many nights of losing sleep over maintaining and updating python libraries and dependencies, he chooses the best cloud-based service, Google Collab. There are dozens of cloud-based Jupyter Notebook providers, e.g., AWS SageMaker, Microsoft Azure, Gradient, Kaggle, etc.
10 — Query RAM for GPU and CPU
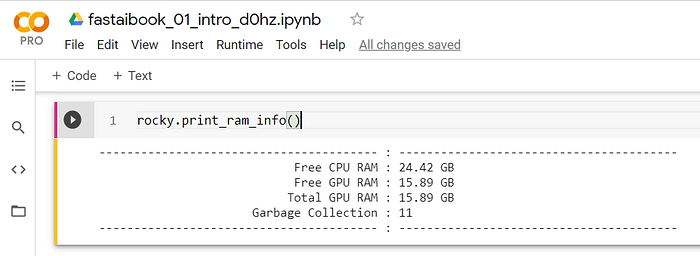
Rocky wants to know what is the GPU and CPU available RAM. While at it, he will issue the garbage_collection() method too.
11 — First Look at Fast.ai 2.0
Rocky is well-versed in Fast.ai 1.0, so he is impressed when he sees version 2.0 in action. Rocky read Fast.ai’s “A Layered API for Deep Learning” peer-reviewed paper outside of the notebook. It’s a three layers architecture with a fantastic call-back mechanism.

Before refactoring the code into Rocky’s objects, he will visually compare version 1.0 and version 2.0. Warning, the picture will look more like a diagram of a cat drawing version 1.0 path.
Enough talk, let’s play. :-)
Rocky knows the original code is a teaser-code, but he can’t help re-code it and play with the hyper-parameters. Why is the code so specific to this one example? Should the method be more flexible or more general? So that Rocky does not need to recode it for the next example.
The answer is to refactor the code that would require a deeper understanding of ANN, Fast.ai, and hundreds of other concepts. Rocky will learn it in chapter 2 to 11. As an analogy, it is the first time Rocky learn to play canine baseball, so it doesn’t matter if he knows the rules, budding the ball with his head, chasing the ball, or chewing Homebase. Just do it.
Furthermore, Rocky is a good programmer, and therefore, code, recode, and code again is what he likes to do. He loves to code on a sunny day, on a rainy day, and twice on Sunday. For now, the only four hyper-parameters exposed are as follow:
- The percentage of the images set assign for validation. The normal is 80% to train and 20% to validate. What if Rocky does 50% training and 50% validation, or 95% and 5%?
- The base-architecture is the essential ANN concept for “transfer learning.” Rocky is jumping ahead in using transfer learning, so just do it. Possible value are “resnet18, resnet34 (default), resnet50, resnet101, and resnet152.”
- The number of epoch to be run. The default is four. What if Rocky runs more epochs or run fewer epochs?
- Image size. The default is 224x224 pixels. What if Rocky increases the image size or decrease it?
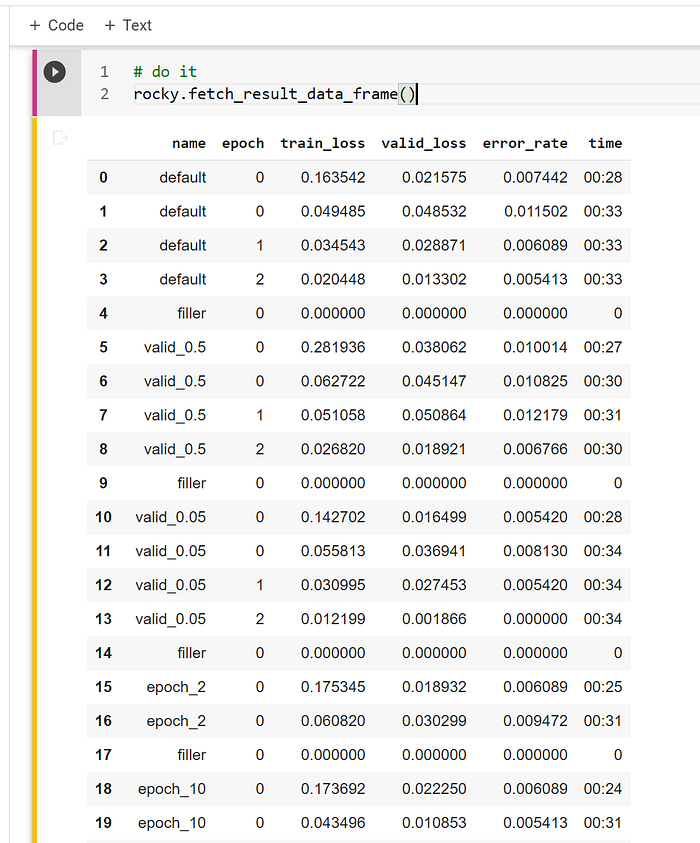
WOW, Rocky trained for six epochs, and the loss-rate is 0.00067, which is 99.933% accuracy. It beat the world-class competition a few years ago.
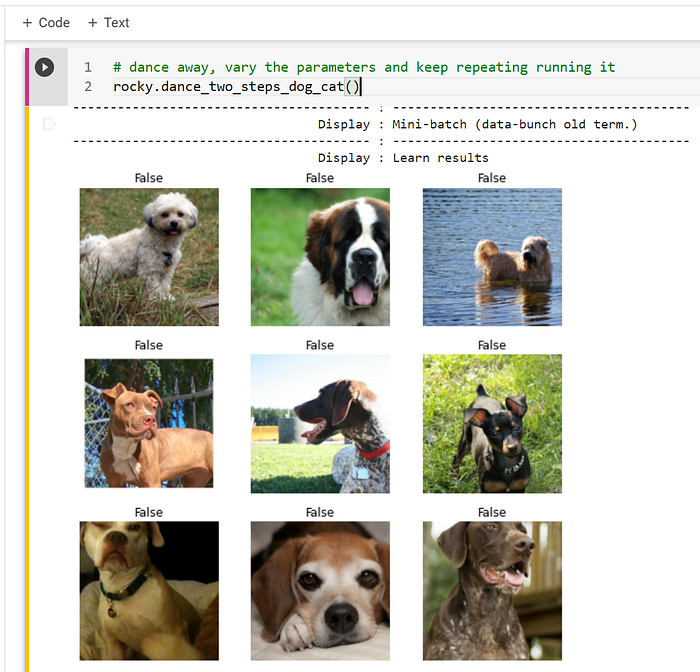
To put it in perspective, the Fast.ai code is a world-class ANN model. In other words, the above code is not a “toy” or “small sample” code. It is the trained ANN model entirely. Comparing to the world Kaggle’s “Dogs .vs. Cats” competition a few years ago, the top three in the leaderboard are “Pierre Sermanet” with 98.914%, “orchid” with 98.308%, and tie for third “Owen & Paul Covington” with 98.171%.
The Kaggle’s competitions are open to top AI researchers worldwide, universities, and enterprise companies, e.g., Google, Facebook, Microsoft, etc.
Rocky achieves 99.933% accuracy. That is 1.019% better. It is a huge jump forward. It is like winning the 100 meters race by 1 second. Rocky could win $10,000 to $100,000 weekly from Kaggle’s competitions if he could time travel back to five years earlier.
- Fetch the “dogs and cats” images. (Figure 12 & 13)
- Train it, and show the results. (Figure 14)
Don’t you glad that Rocky is a dog and not a cat? He can play the “fetch the ball {result-data}” game over and over again. Try to play “fetch” with a cat. :-(
Rocky is not good at drawing, but Snoopy is very good at drawing 2D charts. He wrote the “Demystify Python 2D Charts — A Hackable Step-by-step Jupyter Notebook.”
Snoopy leads a journey on how to draw all kinds of charts. You should jump over there after you complete Rocky’s G1FA journey. :-) Rocky copied only four of Snoopy’s functions to enable him to graph the result data.
That was fantastic fun. Off the bat, here are what Rocky had learned.
- If this is not a competition, or if your boss is a lazy cat who does not know better, Rocky could cheat. He would reduce the “validation” data set weekly to show improvement in the model accuracy. Until he reaches 5%, and amazingly he achieves 100% accuracy. The cat-boss will praise Rocky as the “top dog.” It is so funny, “top dog” or “hot dog.” :-)
- When Rocky tries one or two epochs, the accuracy rate is low but not as low as a fresh start. Rocky resets the system via setting the “learner and dataset” to none and calling the garbage collection method before beginning the training cycle. It should start anew every time, but Rocky has a suspicion that the “trained parameters” are not clear from the GPU RAM. The system reused the “trained parameters” layers, i.e., continue to train and not reset to random weights. Therefore, from the second time onward, the accuracy is high.
- When Rocky tries ten epochs, the accuracy is worsened after the 6th epoch but level out. However, the “train loss” continues to be lower. Therefore, it could signal that the model is overfitting. The big lesson is training the model longer, i.e., with more epochs, does not guarantee a better accuracy rate.
- The next four sets are changing the base architecture hyper-parameters. It is a bit too early for Rocky to explain the advantages of transfer learning in ANN. For now, a short version is that it is an essential breakthrough. It enables ANN to build faster, more accurate, and require less training data.
- The “resnet” architecture has been trained with over a million images. The number following the name is the number of layers in the architecture. The higher the number means the deeper and more complex the model.
- The default is “resnet34,”, i.e., 34 layers deep. It gives an excellent result for any type of ANN model. By trying “resnet18, resnet50, resnet101, and resnet152,” rocky founds a more complex model does not necessarily mean a better result. Many known factors and many more yet to be known factors contribute to the decision on which base architecture Rocky should choose.
- Not knowing yet does not stop Rocky from playing with different base architecture, and he found, for the “dogs and cats” data set, a simpler architecture, “resnet18”, gives a better accuracy rate than “resnet34.”
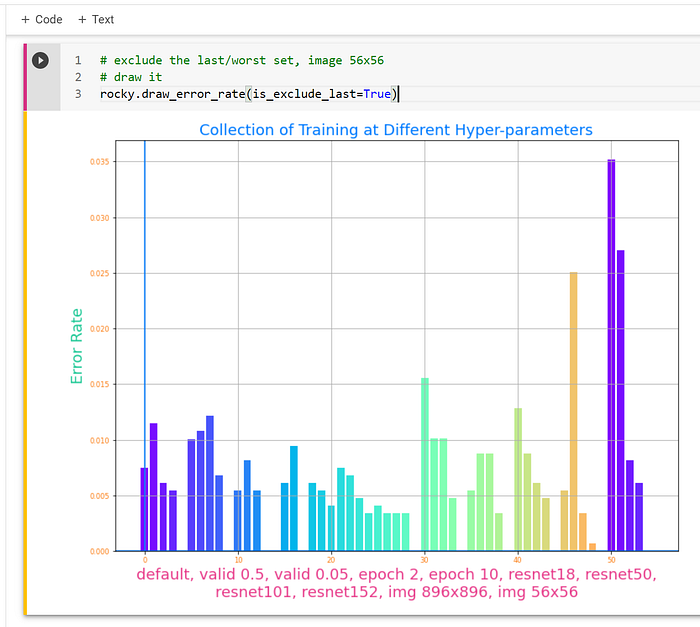
- Perhaps the most surprising finding is that using bigger size images for training does not result in a better result for the “dogs and cats” data set. By increasing the image size to 896x896 pixels, the accuracy rate is less than the default photo size of 224x224 pixels. Furthermore, it broke Rocky’s Google Collab Pro server with the error “…out of GPU RAM”. He has to reduce the “batch size” from 64 to 32.
- Why?
- Before Rocky answers why larger image size gives lower accuracy, he wants to point out that reducing the images to a tiny size of 56x56 pixels gives the worst result as expected. A deeper dive in data-image size and data augmentation is on Wallaby’s “Augmentation Data Deep Dive” journey.
- Rocky doesn’t know the answer [yet]. Maybe one of the gentle readers would tell him. :-)
- Lastly, Rocky could mix and match the four hyper-parameters. He could set the photo size to 1000x1000 pixels, use “resnet152”, change the validation percentage to a ridiculous level of 65%, and train it with 40 epochs.
- Can you guess what could go wrong or what the accuracy rate would be? (it’s easy, hack it.)
11B — Bonus — Label Dog and Cat Breeds (Feb 2021)
Welcome back for the bonus section.
Many have emailed Rocky’s hue-mon {human} companion commenting, “…so what a big deal about identify cats or dogs. Any child can do that…”
It is a common criticism without going into an in-depth technical image recognition explanation, such as the object boundary, the shape of eyes, nose, ears, whisker, and hundreds of other facts comprising a “cat” or a “dog.”
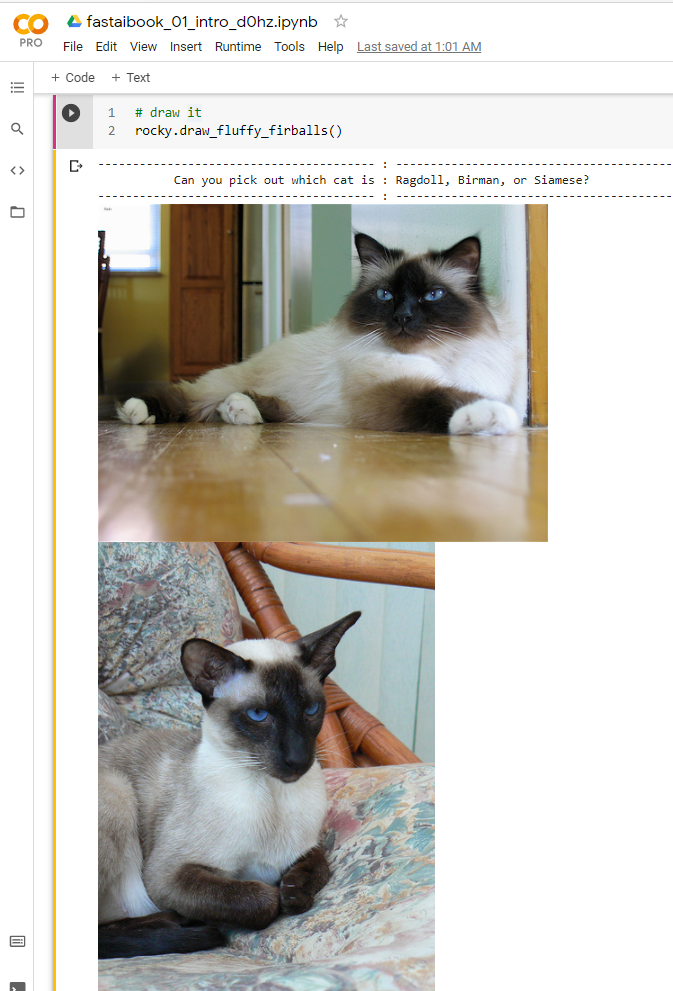
There are thirty-seven different breeds of cats and dogs in the dataset. A hue-mon {human} would take years to study and practice how to classify different breed. For example, can you (a human) identify which of the three images below are Ragdoll, Siameses, or Birman cat? They are all fluffy, white, cute, little furball with black ears and spot on their nose.
It is logical to conclude only one-percent of the hue-mon {human} can correctly identify the 37 breeds of dogs and cats. The experts’ baseline error rate would be about 6%, or the accuracy is 94%.
In other words, 99% of the hue-mon {human} can not identify the 37 breeds correctly 94% of the time. What if Rocky can do it with 94.7% accuracy?
He would be smarter than 99% of the hue-mon {human}. With four additional code lines, Rocky can do it. :-)
You have to admit, that is mind exploding!
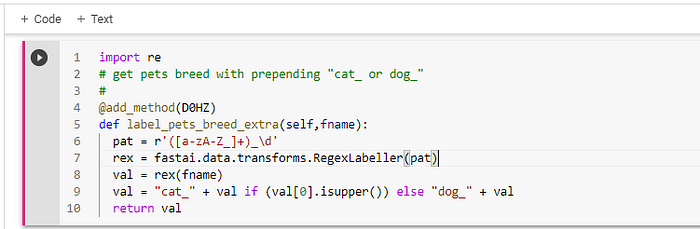
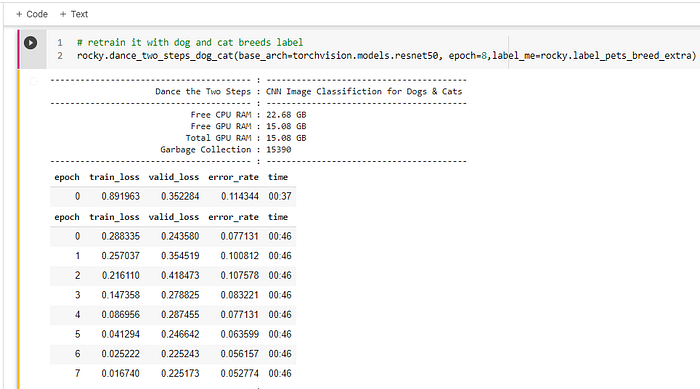
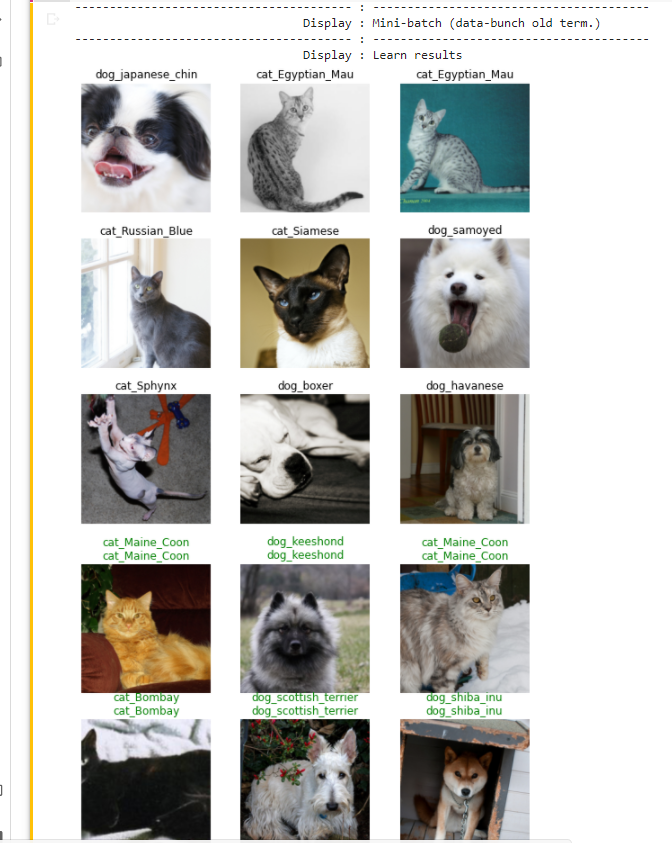

Rocky typically asks you to visit the Jupyter Notebocook version on GitHub, but he will copy the code here for this salient point. Lines #6 to #9 are the magic that turns Rocky to be smarter than 99% of hue-mon {human}. (Figure 17.)
The output of the training session and results are listed below. Remember that all the code for training to label “cat or dog” is the same. Only the additional “label_pets_breed_extra()” function is added to the “dataLoaders.” (Figure 18 & 19)
Furthermore, Rocky could learn to identify all dog breeds, 195, and all cat breeds, 70, with the same AI model, i.e., no additional code needed. All he needs is for the hue-mon {human} feeds the dataset, label-photos for the 265 breeds of cats and dogs.
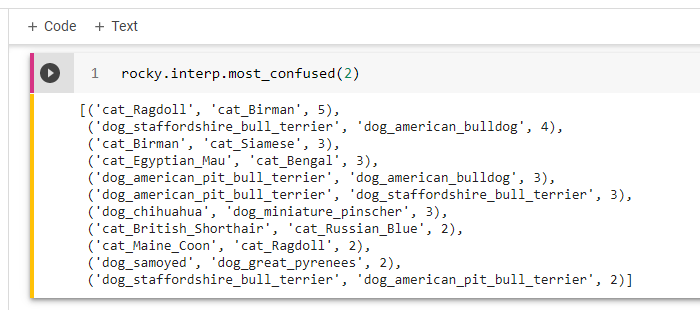
Rocky displays the “Confusion Matrix.” (Figure 20)
Rocky displays the top losses. (Figure 21)
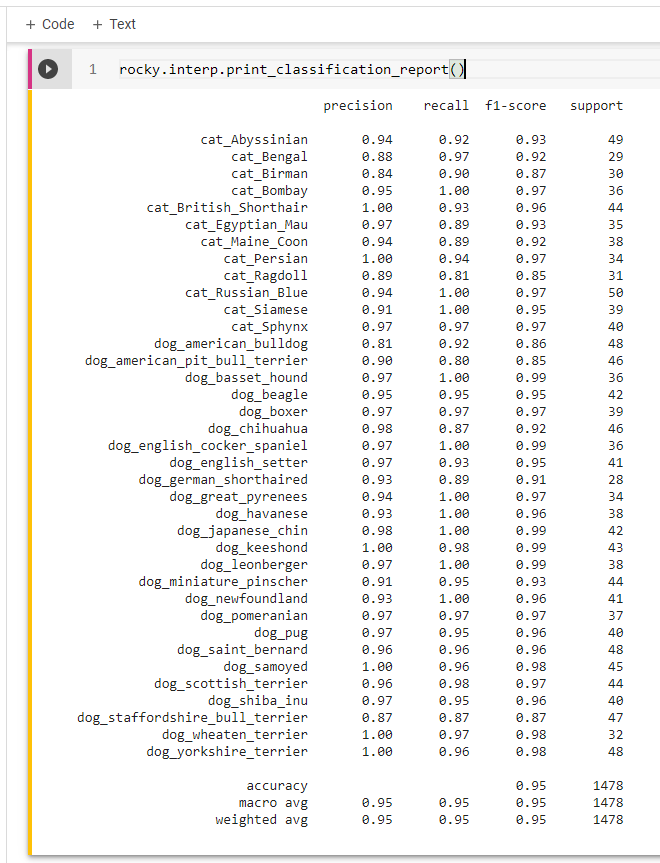
Rocky displays the results in print format. (Figure 22 & 23)
12 — Rocky Refactor the Predict Method (Real-World Testing)
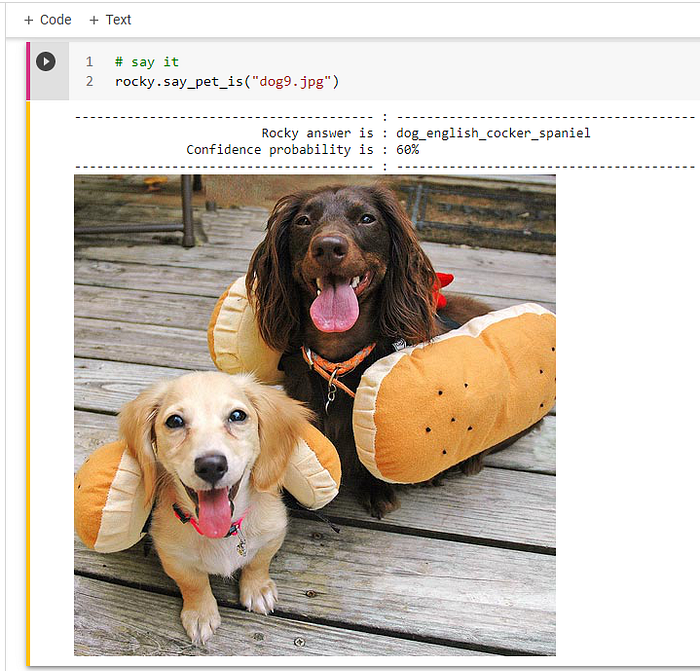
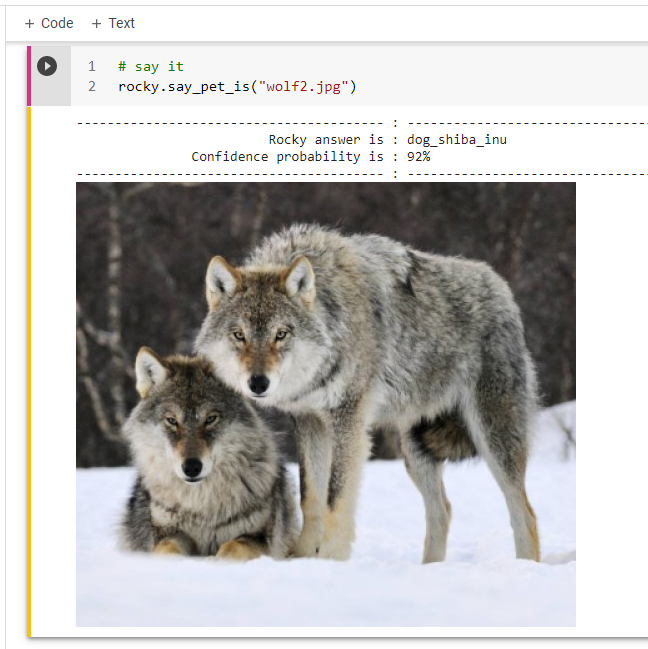
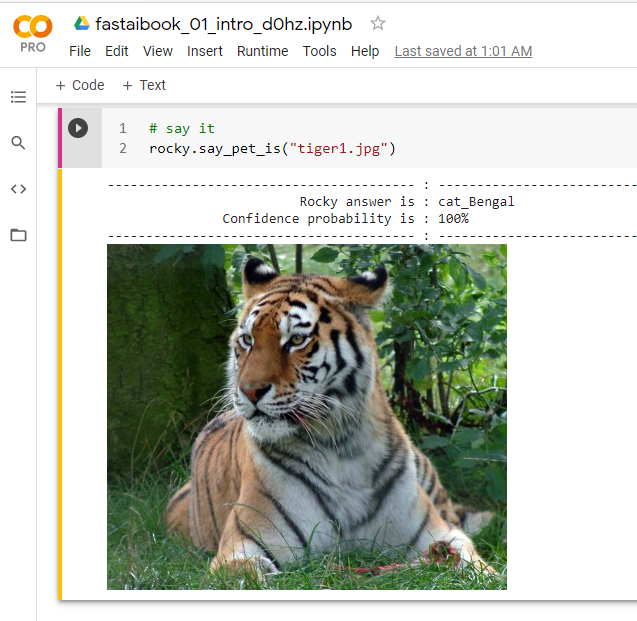
Rocky uploads twenty photos of dogs and cats so he can test them. He is using the default training model. It would be interesting if Rocky would do proper testing. Suppose he would upload one hundred photos and test each of the models.
Remember that in one of the models, Rocky cheated by reducing the validation set to 5%, and he achieved 100% accuracy. This model would give the worst result in real-world testing.
The big lesson is that the best accuracy rate model may not be the best model to deploy. The power of ANN is the generalization, i.e., learn to predict beyond the “training and validation” image set. What if Rocky tests the model with “wolf and tiger” pictures? The good news, the model, classify a tiger as a cat and a wolf as a dog. (Figure 24 & 25)
Rocky highly encourages you to upload your own photos and test them out.
Rocky’s Artificial Neural Network (ANN) is a world-class “dogs and cats” model with 99.93% accuracy. Furthermore, it ables to generalize beyond the data set and predicts wolves as dogs and tigers as cats. :-)
13, 14 & 15 — Visualize Machine Learning and Neural Network Rocky’s Style
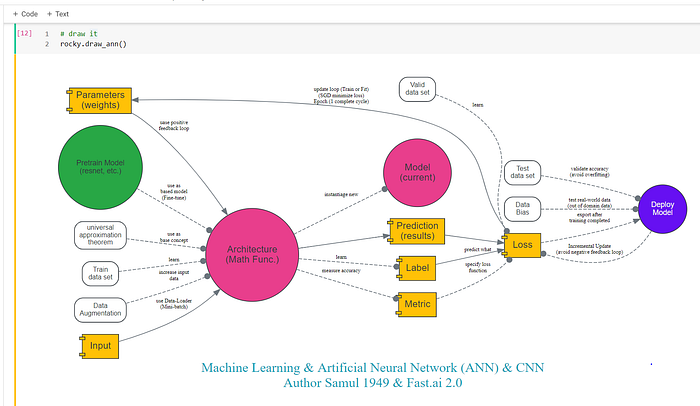
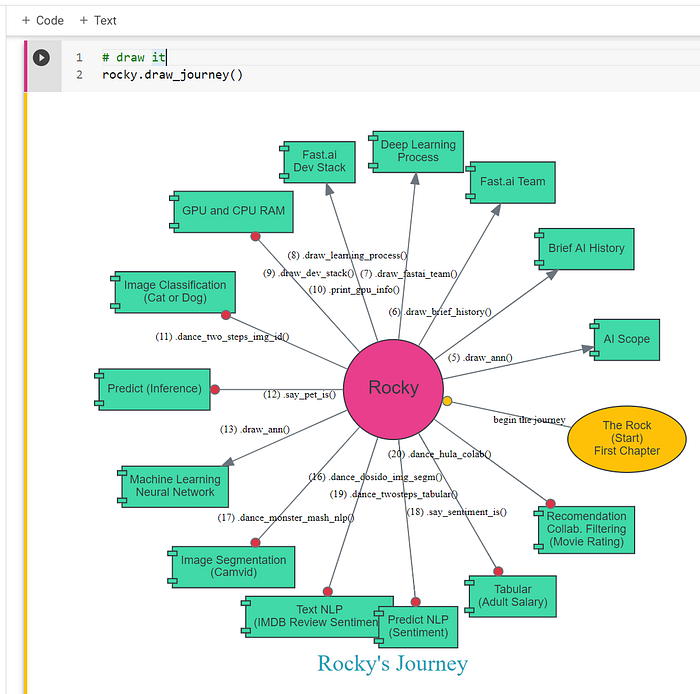
The above original sections are well written with cool graphs, but what if Rocky redraws and combines all the diagrams and the jargons in one mind-map picture?
The result is pretty cool too.
Rocky read the “Fast.ai Peer-Reviewed Paper.” It was an interesting read, and since Rocky is a professional canine programmer, he has no trouble understanding it.
Here is the short and detailed version of the “Fast.ai Architecture 2.0.”
Not! the peer-reviewed paper is out-of-bound for the G1FA journey, so you have to read it on the Github version. One more reason to start hacking. :-)
Recap the jargons by redrawing the ANN model. The above 14 jargons are visually displaying in the proper context. (Figure 26)
16 — Recode Segmentation
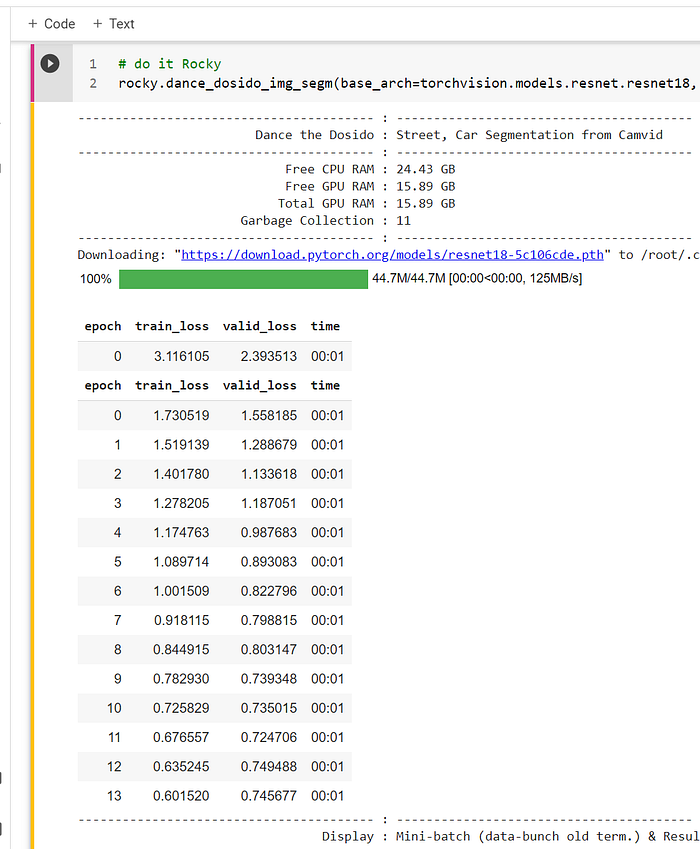

Image segmentation is such a cool concept. In a nutshell, it is identifying objects in a picture. For example, a self-driving car needs to classify objects on the street in real-time, e.g., cars, buses, bicycles, highways, road signs, bridges, people, dogs (but not cats), trees, buildings, and crazy clowns with a red balloon.
Rocky knows that it was impossible to solve the self-driving car problem without using ANN. He will learn more about image segmentation in a later journey.
There are three hyper-parameters, and Rocky will learn about the hyper-parameters in later journeys, but for now, he has fun peaking, poking, and prodding the parameters.
- The base-architecture is the essential ANN concept for “transfer learning.” Rocky is jumping ahead in experimenting with transfer learning, so just do it. Possible value are “resnet18, resnet34 (default), resnet50, resnet101, and resnet152.”
- The number of epoch to be run. The default is four. What if Rocky runs more epochs or run fewer epochs?
- The “batch size” defines how much data will be on the GPU RAM. The default is eight. There are too much data to train all at once, and therefore, the system uses a subset, i.e., a “data bunch” or “mini-batch.” How high can Rocky increase the batch size before the system crashed?
17 — Recode NLP
Natural Language Processing (NLP) is a recent addition to the ANN. Fast.ai introduce NLP in ANN courses about four years ago, and it is fast becoming the go-to solution for language sentiment, language translation, and language categorization.
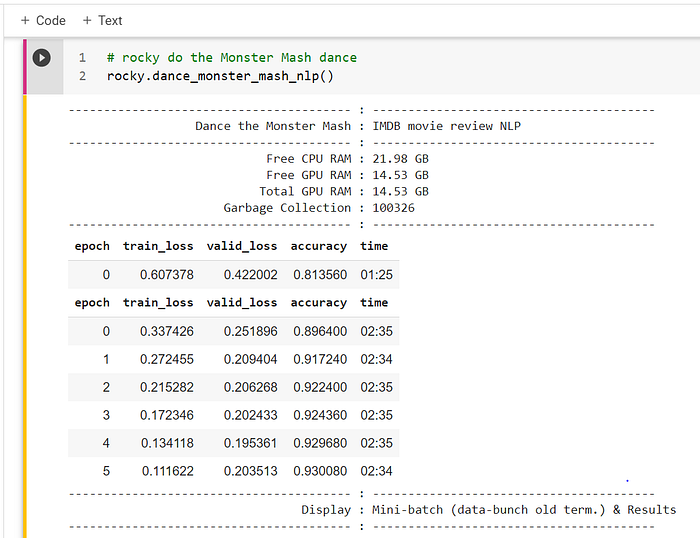
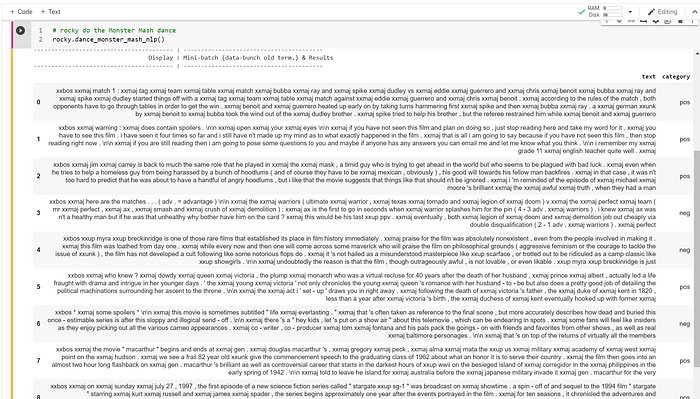
Once again, Rocky knows that he will learn more in the later journeys. The below code is a classic language sentiment problem, i.e., “I like or don’t like,” or “positive or negative.”
The fantastic thing is that Rocky can teach an ANN to classify the sentiment in a sentence or a paragraph correctly without understanding the language. In other words, Rocky does not understand the meaning of the words, and he does not know the grammar rules. Rocky can still program an NLP ANN model with 93% accuracy in identifying negative or positive sentiment. The salient point is without knowing French, Russian, or Swahili, he can teach the ANN to classify negative or positive sentiment in those languages.
Mind Explosion!
Rocky is a canine, so his mind is easily blown. :-)
There are four hyper-parameters, and Rocky will learn about the hyper-parameters in later journeys, but for now, he has fun swinging, slinging, and shimmering the parameters.
- The base-architecture is the essential ANN concept for “transfer learning.” Rocky is jumping ahead in experimenting with transfer learning, so just do it. Possible value are “resnet18, resnet34 (default), resnet50, resnet101, and resnet152.”
- The number of epoch to be run. The default is six. What if Rocky runs more epochs or run fewer epochs?
- The “fit learning rate” is the essential hyper-parameters. The default value for this model is 0.01. Four or five years ago, it was the hyper-parameter that held back the explosive growth of ANN. More than others, if Rocky chooses the “fit learning rate” slightly too big, e.g., 0.666 instead of 0.01, the model will fail to converge. Luckily, Rocky will learn how to choose the correct fit-rate based on the training data. What fit-rate value do you think would blow up this model? Go ahead and try it. :-)
- The “dropout rate” is yet another hyper-parameters that Rocky will learn in the later journeys. The default value is 0.5. Conceptually, it is easy to understand. It is “how much do you want the model to forget?” How and why will take longer to explain. What if Rocky tells the model to forget everything, i.e., set the dropout rate to zero, or to remember everything, i.e., set the dropout rate to 1.0?
How was your hacking with the above hyper-parameters? Rocky tries different hyper-parameters values with mixed results. He wants to do a deep dive into the “how and why” do the hyper-parameters works.
If you found something great or just odds, please connect to Rocky’s hue-mon {human} friend on LinkedIn and share them with him.
18 — NLP Predict
Rocky is amazed that it works. He has to test it with real-world data.
It’s alive!
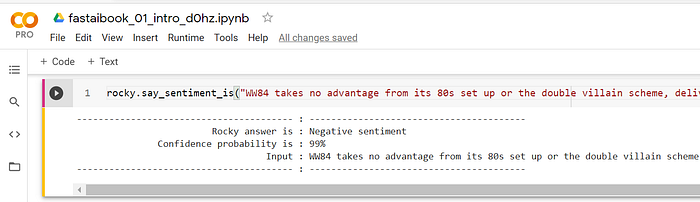
Rocky copied the current movie reviews, which are not in the training set, and it correctly classifies the sentiment. Rocky wrote a short movie review, “I hate this movie,” and the model classifies it as “negative sentiment.” He wrote a glowing 100 plus words review of an imaginary movie, and it also correctly classify as a “positive sentiment.”
Please try it yourself.
This is why Jupyter notebook is so great at learning AI. It is like reading a cookbook with a 3D-Food printer. Read about how to bake an apple pie and presto. You can eat the pie. “The proof is in the pudding.” That is so funny. :-)
*Disclaimer, Rocky has not yet invented the “3D-Food printer.”
19 — Tabular Recode
Tubular data are data store in rows and columns, for example, a table, a matrix, a Rank-2 tensor, or a two-dimension array. It is like a spreadsheet or relational database. Machine learning, e.g., “Random Forest” methodology, is the default solution for tabular data prediction, but ANN can do it well too, and maybe can do it better.
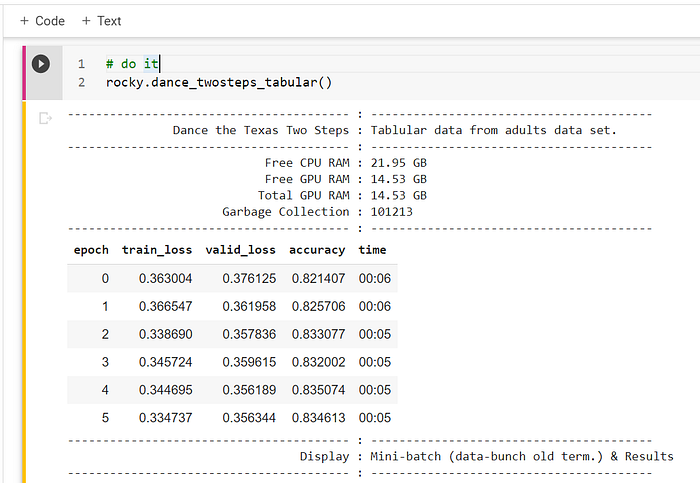
Using nine categories, i.e., the “work-class, marital status, occupation, relationship, race, education, age, weight, and education level,” the ANN will predict the employee salaries is greater (encode as one) or lesser (encode as zero) than $50,000 a year. Is there an innate relationship between these categories? For example, if higher education results in higher salary or if younger results in lower wage?
How does ANN able to predict without needing to understanding the data relationship? Rocky said they are good questions, and they won’t be answered until the fourth or fifth journey.
There is one hyper-parameter, and Rocky will learn about the hyper-parameters in later journeys, but for now, he has fun chasing, chewing, and chucking the parameter. The number of epoch to be run. The default is six. What if Rocky runs more epochs or run fewer epochs?
20 — Recommendation (Collaborative Filtering) Recode
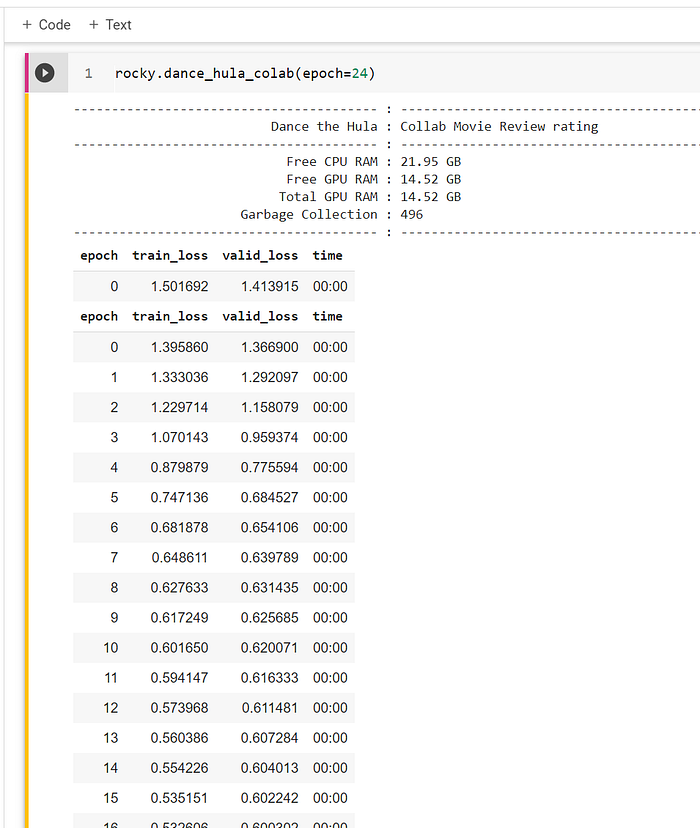
Recommendation or collaborative filtering is predicting the result in a range of numbers. This example predicts the user rating for a movie from a range of 0.5 to 5.5.
The process for training an ANN for recommendation is similar to the above tubular method. There are two hyper-parameters, and Rocky will learn about the hyper-parameters in later journeys, but for now, he has fun wiggling, wrangling, and wielding the parameter.
- The number of epoch to be run. The default is six. What if Rocky runs more epochs or run fewer epochs?
- The target range is the range for the prediction result. The default is 0.5 to 5.5. The labeled data range from 1.0 to 5.0, so selecting the target range is not much choice.
22 — Rocky Wrap Up
It is an “introduction to Fast.ai” journey, but when Rocky digs deep, writes, and re-codes, he learns so much more.
Fast.ai version 2.0 is a powerful platform for ANN. Rocky founds that it is easier to learn than Google’s TensorFlow, Amazon’s SageMaker, or Keras. Rocky is experienced in Fast.ai version 1.0, and he appreciates the complete 2.0 rewrite. The concepts are the same, and the code architecture is more formalize using the standard software API metaphor. Rocky can’t wait to dig deeper into the three-layer architecture, especially the “data-block, data-loader, learner” classes and the “callbacks” methods.
Rocky hopes you like the mind-map diagrams for summarizing the concepts, jargon, and history. He has fun hacking the original codes, refactoring them into class methods, and exploring the hyper-parameters. Even though the book does not explain the hyper-parameters in chapter one, by experimenting with trying different hyper-parameters, Rocky gains the knowledge. He will have a deeper understanding when he reads the hyper-parameters explanation on later chapters or additional white papers.

The “Graphviz” is a powerful library for mind-mapping. It is so much better than PowerPoint and other GUI tools because why drag-and-drop when you can code. :-) There is a no better visual method than summarizing the journey with a friendly, informative diagram.
Rocky is looking forward to the next journey and hopes to see you again.
The End.
23 — Conclusion
We can use any measurable goals to verify a study group’s success, and the hands-down Jupyter notebook is the key enabler. Granted that the G1FA study group members are successful and knowledgeable AI and data scientists, but through the sharing of individual notebooks, we can cross-check, hack, recode, comment, and maybe, just maybe, learn from each other.
I encourage my colleagues to share their notebooks on Github, LinkedIn, or a blog of their choosing. No one says “no,” but that does not mean “yes.” I wish we would live in a binary world. :-) I think they would publish their notebooks or a portion of their notebooks when we deep-dive in the Fast.ai platform in the later chapter.
Fastbook chapter one is an introduction chapter (hardcover book). The primary purpose is to get the readers excited about AI and see for themself how to build a world-class Artificial Neural Network (ANN) model, not just a toy or sample codes. AI students and IT professionals curious about transitioning to a career in AI should found the G1FA journey informative.
I have worked using Google’s TensorFlow, Keras, Microsoft Dynamics 365 AI, and Amazon’s SageMaker. I found Fast.ai version 2.0 is a better option for AI developers and scientists because it is easier to learn, opensource, and having a substantial interactive community. You can develop, debug and research as deep in the code as needed.
Fast.ai demystifies ANN by explaining the rules and not relying on memorization. Other AI platforms or AI courses depended on memorizing terminologies and theories. They lack the practical guidance in coding and deploying real-world ANN applications.
It is like learning to play chess by first learning how each chess piece moves, having fun playing the game, and not worrying about memorizing, such as the “Sicilian defense.”
At the time of publishing the G1FA Rocky’s notebook, our group has collectively completed chapter seven in the book, and a few are even ahead to chapter ten. The second study group, codename VxFA, is in chapter three. The study group does not exclusively belong to the domain of students. The professionals are just as likely to learn better in the company of friends.
In chapter two, I took a left turn and dived deep into the data structure of “DataBlock, DataSets, and DataLoaders.” In chapter four, the “gradient descent” concepts, coding, and maths are easy to understand, but I felt off the cliff pontificating “why does it work” so well for ANN. It’s not causality, so I wrote pages and pages of code, desperately trying to convince myself. Similar discoveries are found in the later chapters. I will clean up those notebooks and publish them when I have time, or better yet, the GxFA group member could beat me to it by publishing their notebooks.
When you are in a good ANN course, e.g., the Fast.ai “Practical Deep Learning for Coders,” what you learn is not abstract. I am using it in my daily professional work. Now you know that the greatest AI scientists fear is being obsolete. It should not be a surprise that my colleagues and I form a “study group,” like kids in a sandbox.
As the author, I layout the journey beginning, middle, and ending, but through Jupyter Notebook, the readers can, and even encourage to, hack the story by adding notes, modify the codes, or write the new detour.
Not all AI scientists are working for Microsoft, Amazon, Apple, or the government Defense Department on large-scale omnipotent AI. If we are in the Star Trek universe, these are not the First Officer or Chief Medical Officer’s flagship logs. They are the logs of a non-commission mechanic charting star course between a dead planet and the ship boneyards.
I hope you enjoy reading it, sharing it, and giving it a thumb-up. I will see you on the next Demystify AI journey.
Epilogue
2020 was the year where fake news and misinformation became mainstream. Unfortunately, I have read too many highly polarized articles about mistrusting AI on social media and the mainstream news channels. These fears are misplaced, misinformed, and fractured our society.

Doing nothing is not the same as doing no harm. Therefore, we can’t opt out and do nothing, so I take baby steps. The notebooks are not about large-scale omnipotent AI. Instead, they demystify AI by showing the mundane problems facing AI scientists in a real-world project. It is like demystifying crabs-fishermen by watching the TV series “Deadliest Catch.”
“Do no harm by doing positive deeds” is the foundation reason why I write and share the demystify AI series. The articles are for having fun sharing concepts and code with colleagues and AI students, but more than that, it is for building trust between AI scientists and social media.
I hope you enjoy reading it, sharing it, and giving it a thumb-up.
<<I published this article in LinkedIn first>>
Demystify AI Series
- Hot off the press. “AI Start Here (A1SH)” — on GitHub (July 2021)
- “Fast.ai Book Study Group” on LinkedIn — on GitHub (January 2021)
- “Deep Learning Augmentation Data Deep Dive” — on GitHub (December 2020)
- “Demystify Neural Network NLP Input-data and Tokenizer” on LinkedIn | on GitHub (November 2020)
- “Python 3D Visualization “ on LinkedIn | on GitHub (September 2020)
- “Demystify Python 2D Charts” on LinkedIn | on GitHub (September 2020)
- “Norwegian Blue Parrot, The “k2fa” AI” on LinkedIn | on K2fa-Website (August 2020)
- “The Texas Two-Step, The Hero of Digital Chaos” on LinkedIn (February 2020)
- “Be Nice 2020” on Website (January 2020)
